
Brown University's Net-Positive Carbon Goals
On August 5th, 2025, as a part of the fallout from the second Trump administration’s attack on higher education, Brown university announced that it was pausing its climate goals. Amidst the chaos and uncertainty surrounding the NHS grant freeze, and the looming threat of constant legal troubles, their climate goals were the easiest thing to deprioritize. At the time, this didn’t receive much attention, with more focus directed toward the existential crisis Brown had been thrust into.
But even after signing an agreement with the federal government and the subsequent return of NHS funding, Brown still has yet to reinstate its previous climate goals. This alone is, I think, something to criticize. We need, now more than ever, to work toward mitigating climate change as much as possible on every axis. Letting our dreams of a net-zero campus fall by the wayside isn’t something to feel proud of.
All of this happened to coincide with a global fervor for so-called “Artificial Intelligence” (AI). Universities have never been immune to corporate buzz words, but AI especially seemed to reorient all of Brown around it. As a member of research staff here at Brown, the pressure from on-high to use, develop, and even promote AI is inescapable.
From my perspective, this is most evident when talking about Oscar, Brown’s supercomputer. This is a cluster of compute nodes that exists to facilitate research here, allowing anyone access to the high performance hardware needed to run complicated software or perform intricate data analysis. But even though we haven’t hit the ceiling of what Oscar can handle right now, there are still conversations about expanding Oscar with new GPU nodes — something that feels clearly motivated by the need to keep pace in the ever expanding AI race.
Oscar’s Environmental Impact
So let’s actually do some math and examine Oscar’s carbon emissions.
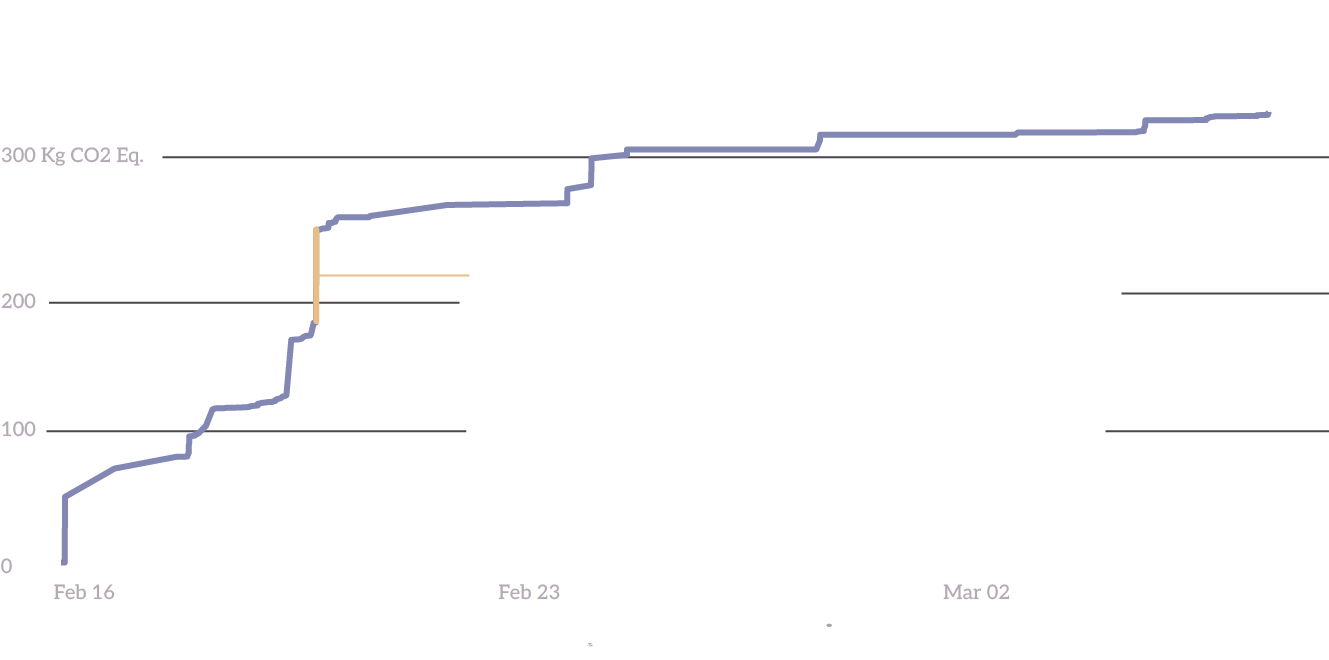
While all computers use electricity (and emit carbon as a byproduct of that energy production), not all computers consume electricity at the same rate. For example, mobile computing devices are optimized to consume as little electricity as possible to prolong battery life. On the other hand, compute nodes used in super computers are optimized for high performance and data throughput. But even here, we can draw distinctions between CPU nodes and GPU nodes.
GPUs (graphical processing units) are specialized to process matrix operations quickly and efficiently. And coincidentally, AI tasks require computers to perform many large matrix multiplications. But GPUs are even less optimized for power consumption than CPUs, and as a result emit much more carbon.
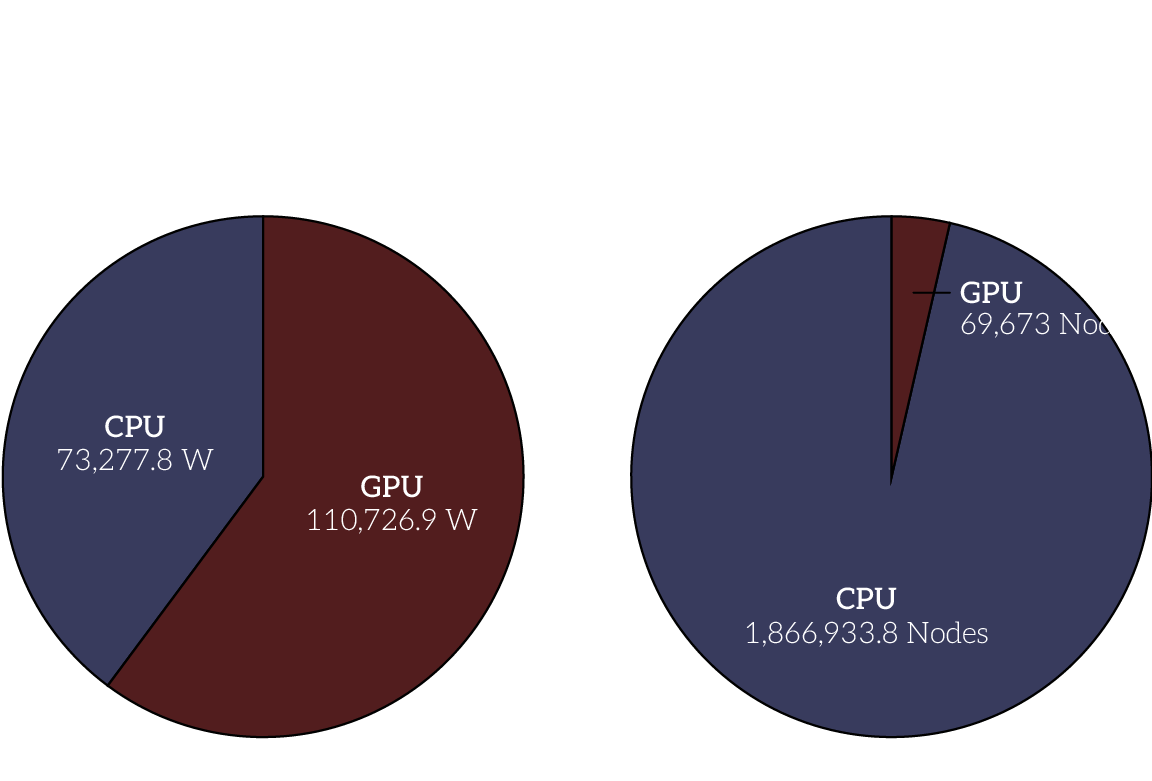
When talking about power usage on Oscar (and carbon emissions as a byproduct), it’s downright misleading to not acknowledge the disproportionate impact of GPUs. Despite making up only 3.5% of allocated nodes each month, GPUs make up 60% of the total energy used by all compute nodes in the cluster. Given that much of an outsized impact, I think it’s reasonable to wonder if the energy being spent to power those GPUs is worth it.
Unfortunately, with the data we have access to right now, it’s hard to know what precisely these GPUs are being used for. While AI tasks require GPUs, that doesn’t mean that people are just using Oscar as a free way to run Large Language Models (though that’s certainly a possibility 🤡). But because we can’t know, I’m hesitant to claim that the energy used by Oscar is frivolous or wasted. In an ideal world, researchers and scientists should have access to the tools they need — but research, and its underpinning infrastructure, needs to be sustainable. And at least with respect to Oscar, I don’t know if it is.
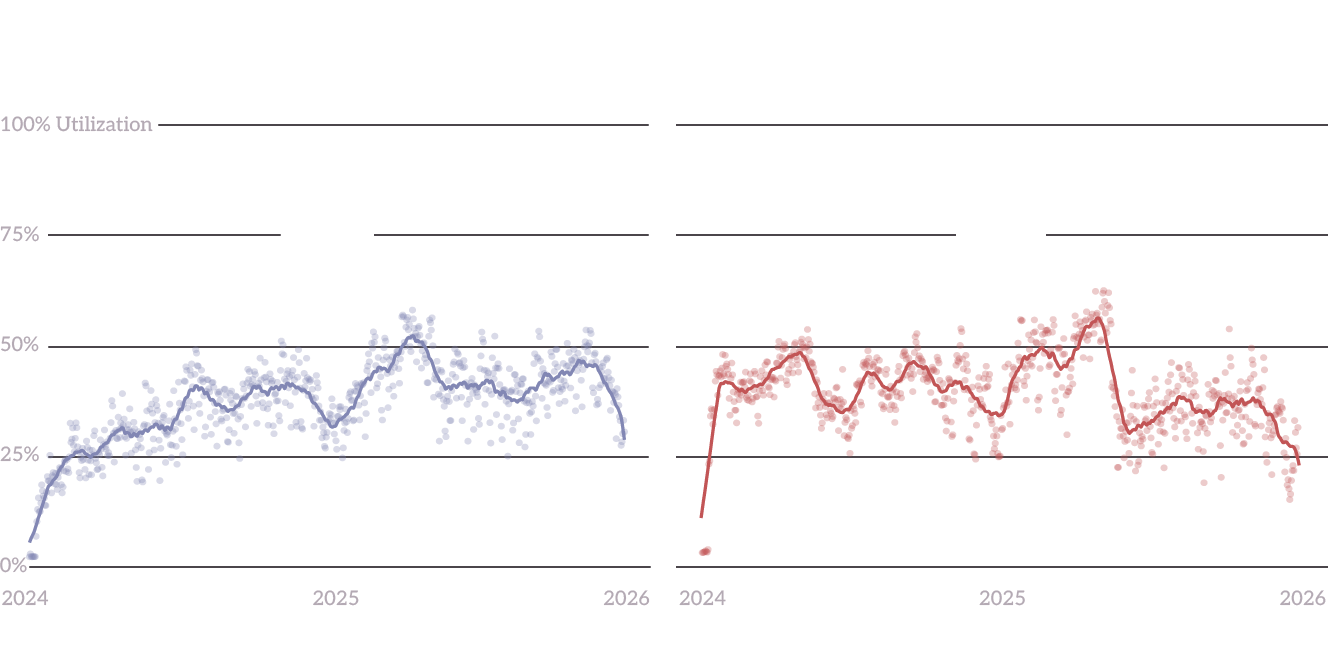
With ongoing efforts to expand Oscar happening while we have only an average of 38% utilization is a little strange. As it stands right now, we should have the compute capacity to grow research for a while before needing to acquire new hardware. So, if we don’t need the hardware for research, what is the real need for this hardware?
Why do we even need a supercomputer?
The crux of the problem is that Oscar isn’t just a tool for research. Its existence also serves to bolster Brown’s clout. In the age of cloud computing, it’s not clear that private research institutions actually even need their own computing clusters for research — surely Google, Microsoft, and the like would have better access to state of the art hardware than a private educational institution. But, for Brown, there’s power in simply owning the hardware and being able to say community members have access to a super computer. Being perceived as an elite institution is leveraged into more dollars for the university, turning investments in Oscar into normal university advertising. The overall number of compute nodes in Oscar doesn’t matter, so long as it’s at least competitive with the super computers at Harvard and MIT.
As a result, the carbon emitted by any one job run on Oscar is less important than how much we’re growing Oscar. According to NVIDIA, manufacturing an HGX H100 emits 1,312 kg CO2e. Because of this, adding even one H100 GPU (assuming it’s never even turned on) would be similar to running four months of CPU jobs on Oscar. And often, expansions of supercomputers don’t happen in increments of one or two GPUs.

But just because emissions from jobs are less important doesn’t mean we should discount them either. If we want to use and operate a supercomputer like Oscar sustainably, we need to account for both the costs of our own compute and the infrastructure that enables it. This means digging into the data and understanding our own contributions to carbon emission. This means recognizing that Oscar is just one of many research tools at Brown, all of which need to be used with intentionality and purpose. And this also means holding university administration accountable for decisions motivated by the allure of prestige without acknowledging the actual needs of the research community.
Data Notes
The data for this project came mostly from two of Oscar’s internal databases. The Slurm database tracks a history of all jobs run on the supercomputer since 2024, the resources allocated to those jobs, and some other metadata. The Prometheus database tracks, among other things, power data for each hardware node in the cluster. These datasets are too large to link here, but if you’re curious to explore the data yourself, email support@ccv.brown.edu. Abbreviated versions of the datasets used to create the visualizations on this page are available for download:
The Carbon Emissions Per Job dataset might benefit from a little more detailed explanation. This uses the Green Software Foundation’s Impact Framework to combine metadata from the Slurm database with real power readings from the Prometheus database as well as grid carbon data to create an analysis file. Because this analysis requires real power readings, we’re only able to get carbon numbers for recent jobs (within 30 days of analysis). With an analysis file for each job, they can be analyzed to create the CSV above. The idea behind the Impact Framework is to combine data, methodology, and result in a single file. You can download an example carbon analysis file if you’re curious to explore more!